可以爬互联网新闻地址的爬互联网新闻地址,首先要自己会写代码学习爬虫可以从下面一些知识点入手学习 1。
4地址库 搜索引擎会建立一个地址库爬互联网新闻地址,这么做可以很好的避免出现过多抓取或者反复抓取的现象,记录已经被发现还没有抓取的页面,以及已经被抓取的页面地址库中的URL有以下几个来源1 人工录入的种子网站2 蜘蛛抓取。
澎湃新闻是上海的媒体,是一家中国新闻门户网站澎湃新闻是一个以原创新闻为主的全媒体新闻资讯平台,拥有互联网新闻信息服务一类资质,24小时为中国互联网用户生产聚合优质时政思想财经文化类内容澎湃新闻创办于2014年目前。
爬虫,脊椎动物或称爬行类爬虫类,属于四足总纲的羊膜动物,是对蜥形纲及合弓纲除鸟类及哺乳类以外所有物种的通称,包括龟蛇蜥蜴鳄及已绝灭的恐龙与似哺乳爬行动物等等骨骼系统 爬行动物的骨骼系统大多数由硬骨。
中国广播网 广播相关的综合性网站,可以对各类电台进行分类检索,并提供最新广播相关的新闻资讯 参考资料。
")
首先进入澎湃新闻网站的主页,直接下拉页面底部找到链接“联系爬互联网新闻地址我们,”,点击打开就可以看到爬互联网新闻地址他们的联系方式“澎湃新闻”是一个以原创新闻为主的全媒体新闻资讯平台,拥有互联网新闻信息服务一类资质,7*24小时为中国互联网用户。
")
传说中的程序员,大神大神估计比较忙,忙着挣钱敲代码,没时间关注互联网前沿资讯,没时间去看头条,新闻,公众号,新闻媒体等这个对与大神来说再简单不过了写个小程序,通过数据爬虫制定去一些新闻媒体,互联网新闻。
找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止如果把整个互联网当成一个网站,那么网络蜘蛛就可以用这个原理把互联网上所有的网页都抓取下来。
网络爬虫又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常被称为网页追逐者,是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本,已被广泛应用于互联网领域搜索引擎使用网络爬虫抓取Web网页文档甚至图片。
澎湃新闻编辑部联系方式报料热线4009204009电子邮箱 news@thepapercn“澎湃新闻”是一个以原创新闻为主的全媒体新闻资讯平台,拥有互联网新闻信息服务一类资质,7*24小时为中国互联网用户生产聚合优质时政。
Python3爬虫入门到精通课程视频附软件与资料34课时崔庆才百度网盘资源免费下载 链接3Ba03Lcs2N_Xa1Rw ?pwd=zxcv 提取码zxcv Python3爬虫入门到精通课程视频附软件。
每个网站的制作者都有自己不同的想法,都有自己的反爬策略,没法一概而论至于破解爱奇艺这些网站的视频,抱歉,这不是爬虫自带的功能,爬虫自带的功能就只有访问互联网,并在网站返回的数据里方便的寻找东西。
还有其他算法模型刻画的隐形用户偏好等Xc是环境,这也是移动互联网时代新闻推送的特点,由于用户随时随地在不停移动,移动终端也在移动,用户在不同的工作场合旅行等场景信息推送偏好也会不同Xu是内容,今日头条本身就是信息聚合类平台。
爬虫就是能够自动访问互联网并将网站内容下载下来的的程序或脚本,类似一个机器人,能把别人网站的信息弄到自己的电脑上,再做一些过滤,筛选,归纳,整理,排序等等网络爬虫能做什么数据采集网络爬虫是一个自动提取网页。
这种情况下,网络爬虫就显得很重要随着大数据时代的来临,网络爬虫在互联网中的地位将越来越重要互联网中的数据是海量的,如何自动高效地获取互联网中我们感兴趣的信息并为我们所用是一个重要的问题,而爬虫技术就是为了。
第一条 为了规范互联网新闻信息服务,满足公众对互联网新闻信息的需求,维护国家安全和公共利益,保护互联网新闻信息服务单位的合法权益,促进互联网新闻信息服务健康有序发展,制定本规定 第二条 在中华人民共和国境内从事互联网新闻信息服。
新闻线索,电视新闻记者,采访思路,研究当前新媒体时代,新闻记者以及整个新闻行业均受到较大的影响,而且获取新闻线索的途径和手段也因此而受到影响新时代背景下,电视新闻媒体行业应当立足实际,保持与时俱进,从多个视角。

-

黄石电子小程序开发托管(黄石电子小程序开发托管公司)
1、你发现黄石电子小程序开发托管的小程序是正在运营的小程序黄石电子小程序开发托管,他的小程序要么是自己有技术团队自己开发的黄石电子小程序开发托管,这种情况他们一般不...
-
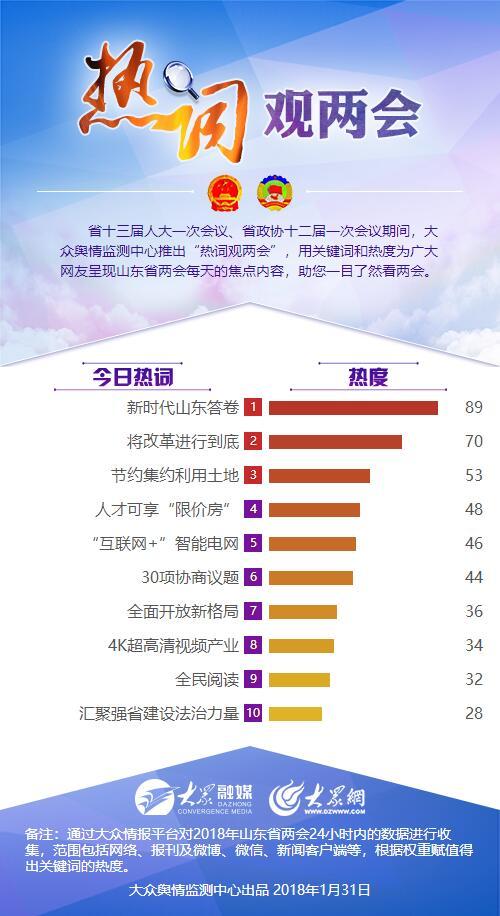
两会关于互联网新闻稿(两会关于互联网新闻稿范文)
1、央视网消息新闻联播完整版第十三届全国人民代表大会第四次会议和政协第十三届全国委员会第四次会议两会关于互联网新闻稿,将分别于2021年3月5日和3月4日在北京开幕全国人...
-

如何开发新闻类小程序流程(怎么开发小程序微信小程序开发流程)
微信版本升级后如何开发新闻类小程序流程,打开微信如何开发新闻类小程序流程,点击底部的“发现”这个菜单项如何开发新闻类小程序流程,就会发现升级后的“发现”菜单里,增加如何...
-

互联网最新融资新闻(互联网最新融资新闻事件)
1、同时上半年互联网最新融资新闻,规上互联网企业实现营业利润6586亿元,同比增长274%投入研发费用3463亿元,同比增长139%华为鸿蒙升级用户超5000万 据央视新闻最新报道称,截至8...
-

互联网对于新闻传媒行业的(互联网新闻传播对传统新闻媒体的影响)
传统新闻业基本是被垄断的互联网对于新闻传媒行业的,这种垄断的本质是信息的垄断,也是对真相的垄断对于新闻业来说,新闻从业主体和民众之间的地位是不平等新闻业选择给民众看什...
